Falhas em discos rigidos
Em 2007, o Google publicou na conferência “Proceedings of the 5th USENIX Conference on File and Storage Technologies (FAST’07)” um artigo muito elucidativo sobre falhas de disco. Os dados foram obtidos das suas quintas de servidores com uma população de 100.000 discos o que permite recolher métricas com algum peso em termos estatísticos.
Tendo eu alguma cota parte de gestor de sistema, este artigo captou o meu interesso e partilho aqui um resumo deste.
O Google tem perto de 100.000 discos rígidos, muitos destes PATA e SATA, os mesmos que utilizamos no nossos computadores pessoais e um facto que sobressai é que temos agora melhores discos para uso “caseiro” do que para uso profissional (FC e SCSI). O artigo apresenta resultados surpreendentes em cinco áreas:
- A viabilidade do MTBF dos fabricantes
- A inutilidade da estatística do SMART
- Carga e tempo de vida do dispositivo relacionados com falhas
- Temperatura relacionado com falhas
A viabilidades do MTBF dos fabricantes
MTBF, Mean Time Between Failure, é uma medida estatística que indica tempo médio entre falhas. Quando um fabricante especifica 300.000 MTBF, isto significa que temos uma probabilidade de falha de 50% antes das 300.000 horas. Se formos positivos, significa que temos 50% do disco não falhar antes durante 34 anos e 4 meses (300.000/365 dias/24 horas). Quando irá falhar? esta métrica nada diz sobre o assunto. Num ambiente ideal, se tivermos 600.000 discos, poderíamos contar com uma falha por hora. No entanto o bom senso diz que o número de falha irá aumentar quando mais perto da média estivermos. O google AFR, Anunal Failure Rate, apresenta um cenário diferente.

Vou continuar esta análise depois de explicar como são obtidas as métricas dos fabricantes.
MTBF definido pelos fabricantes
Não é viável testar um dispositivo de forma “real”. Teoricamente falando seriam preciso mais de 68 anos para poder concluir que o MTBF é de 34 anos ao tentar replicar discos como uso “normal”. Dito isso, a estatística fornece ferramentas para acelerar o processo da seguinte forma. Os fabricantes, na fase de concepção/testes, pegam em muitos discos e dão lhes um uso intensivo até estes falharem. Com base no uso intensivo dado e no uso padrão esperado para os discos, é conseguido uma projecção no tempo de como os equipamentos irão comportar-se. Este teste acelerado é usado tanto na informática como também na aeroespacial, electrodomésticos como no sector automóvel. O problema é que estes testes não representam realmente as condições reais submetidas aos equipamentos:
Since failures are sometimes the result of a combination of components (i.e., a particular drive with a particular controller or cable, etc), . . . a good number of drives . . . could be still considered operational in a different test harness. We have observed . . . situations where a drive tester consistently “green lights” a unit that invariably fails in the field.
Utilidade do SMART
O SMART é uma interface presente nos discos que recolha, analise e tenta prever falhas no disco rígido. É muito útil para verificar, por exemplo, a temperatura. O SMART recolha e cria um registo de erros internos occoridos. No entanto, o SMART foca-se em falhas mecânicas e não electrónicas, como por exemplo falha de alimentação de um circuito interno. Como tal, muitas falhas não são analisadas. Pelos dados recolhidos no Google, 36% das avarias não foram identificadas pelo SMART o que torna este inútil para previsão de falha. Continua útil porque permite detectar algumas falhas mas não devemos depender exclusivamente dele. No entanto o Google consegui fazer uma correlação entre falhas detectadas no SMART e falha no equipamento nos seguintes parâmetros:
- scan errors
- reallocation count
- offline reallocation
- probational count
Uma correlação obtida é, depois da primeira falha de scan, é 39 vezes mais provável de um disco falhar nos próximos 60 dias do que um disco em perfeitas condições.
Excesso de carga = Tempo de vida reduzida?
Seria lógico esperar que com uma maior carga de trabalho os discos tenderiam para ter um tempo de vida reduzido. Mas nos resultados obtidos não é isso que se verifica.
After the first year, the AFR of high utilization drives is at most moderately higher than that of low utilization drives. The three-year group in fact appears to have the opposite of the expected behavior, with low utilization drives having slightly higher failure rates than high ulization ones.
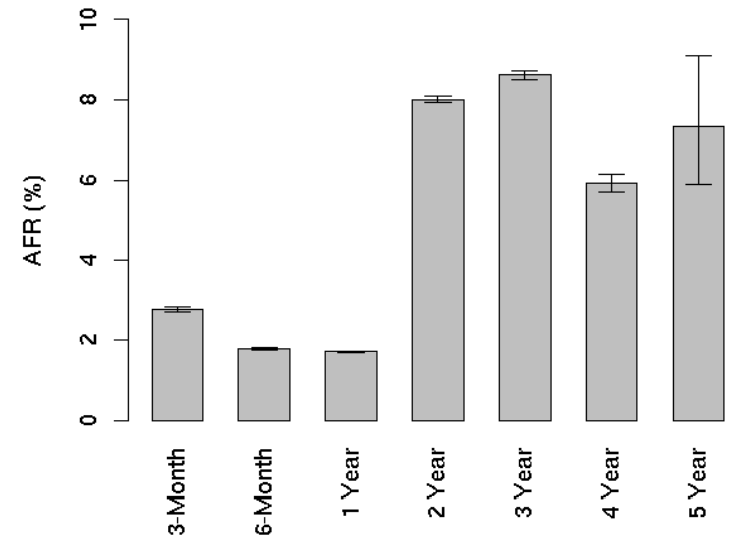

Os resultados são bem claros, os primeiros meses são cruciais quando há excesso de carga. Com o passar do tempo, os discos com excesso de carga tendem normalizar e ter apenas uma taxa moderadamente superior.
Temperatura e falhas
O bom senso diz que quando mais quente … pior. Os fabricantes dão uma gama de operações entre 0º e 60º C e normalmente temos os discos por volta dos 35ºC (+/-5 ºC). No entanto os valores obtidos mostram que é o dobro pior ter discos arrefecidos abaixo dos 20ºC do que acima dos 50ºC.
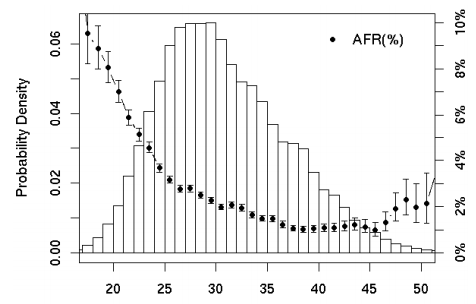
Aqui tenho que admitir que fiquei surpreendido. Isto acaba por ser uma boa notícia aos datacenters e aos gestores de servidores já que ficam com mais espaço de manobra em relação as instalações.
Notas finais:
Não tentar ter um sistema ultra gelado mas sim apenas manter um ambiente normal e controlado (35ºC +-5ºC).
Quando se tem uma drive com carga excessiva, tomar cuidado nos primeiros 6 meses.
Realizar backups regulares e quando houver indícios de erros no SMART, mudar para um novo disco.
Deixe um comentário
Tem de iniciar a sessão para publicar um comentário.